Not dead yet
Sure, Database Mirroring (DBM) has been surpassed by its younger sibling Availability Groups, its full functionality reserved for Enterprise Edition, and it is marked as a deprecated feature. But it’s not dead yet. It’s still a valuable DR option (especially for Standard Edition) and it is an excellent tool for migration projects (hmm, perhaps it could be re-named as Database Migrationing). It’s so useful, I’m not sure MS will every actually get around to removing it and I, for one, hope it lives a long life. Just in case it does, here are a few DBM tricks, tips and hacks I’ve come up with…
(UPDATE: since writing the above I’ve read documentation that AOAG will be available in SQL2016 Standard Edition which is great news. But the limits on SE AOAG include 2 nodes only, non-readable secondaries, and one DB per availability group. DBM is also still available in 2016 SE, but now that the AOAG setup in SE is more or less just like a DBM session perhaps 2016 will be the final version including DBM).
Timeout

Your data is in Wonderland
When you configure the DBM partner via TSQL you have the option to explicitly set the timeout parameter. This is number of seconds the DBM session waits for a ping response from another partner (principal, witness or mirror) before going into panic mode. The default here is 10 seconds. If the DBM session is an HA solution – “full safety” (synchronous) and auto-failover- then 10 seconds is the amount of time the servers can be out of contact before a failover is initiated. On the other hand, for a typical DR pair in “high performance“(asynchronous) mode, the databases will go in recovery or disconnected status, depending on their role, principal or mirror, respectively.
It is pretty common to see TIMEOUT set as the default value. If the session is configured via SSMS, or even a TSQL statement that leaves out TIMEOUT, it’s going to be 10 seconds. This 10 seconds may be about right for a HA implementation, especially if you have a complete auto-failover set-up configured including a witness (which is the only correct way to do auto-failover) and some method to redirect the application connection as well as a high degree of confidence in the network. In short, if we know the partners will never be out of contact for more than 10 seconds, then this 10 second default could work.
But for an asynch DR implementation? Consider that for good DR the mirror instance is remote. This often means a less reliable network, more prone to a glitch or a dropped packet here and there. Also, remember that the DBM session continues pinging even after going into disconnected status. As soon as a ping returns from the partner server the database status’ can cycle back through synchronizing to synchronized. So, really a 10 seconds panic threshold is too sensitive for a DBM DR session in the real world.
It’s not a big deal to just go with the default. The impact is mostly limited to a ‘could not contact DBM partner’ type errors in the error log. But, with a more appropriate setting that error-log noise can be avoided. And we have a much better threshold to build an alert on. Even 60 seconds or more could be a reasonable configuration – i.e. in a DR configuration a 10 second network hiccup that the DBM session recovers from is probably not worth generating an alert, however a 60 second outage sure might be…
And so concludes the most words ever written about the database mirror timeout parameter.
Encryption
By default the database mirror traffic between partners is encrypted, but like the 10 second TIMEOUT, that default value (REQUIRED) might not be ideal. Read up on endpoint encryption here. You could argue the impact of leaving the encryption enabled is negligible and that may be true, but, of course, part of a DBA’s job is to sweat the details. So, if encryption isn’t required it is worth considering turning it off, thereby improving throughput and gaining back those resources spent on encrypting\decrypting. YMMV. If you do go for it, check out this post from Remus R. which has pointers for making an on-the-fly change.
TDE
Since we’re on the topic of encryption here’s a thought on database mirroring and Transparent Data Encryption (TDE). It can be done, no doubt, but be careful combining these two features. In the real world, to stay on budget, it’s pretty common for the DR partner in a high performance mirror session to be somewhat under provisioned – i.e. less CPU, less RAM, slower disk, etc. Remember that TDE data is decrypted when it is read off the disk, and encrypted when written to the disk. Decrypt\encrypt operations may not be a problem for a well provisioned production server, but the DR partner server might be struggling as the mirror session is continuously streaming transaction log records on to disk and all those writes must be encrypted via CPU cycles. Even more so if the DR partner is not the same caliber hardware as the production server. Test the workload before implementation and keep an eye on the CPU use to be sure the DR partner can handle the extra encryption work.
Worker Threads
Back in the old days DBAs used to worry about how many databases could be mirrored per instance before performance issue started to show up. Consensus was no more than 10. That rule didn’t apply for long (SP1 iirc), but there is at least one good reason to keep an eye on how many DBM sessions are up and running. As already mentioned, it’s common to see under-provisioned DR servers. In this case, rather than CPU cycles we are considering worker threads since DBM process’ require several. It’s interesting that the mirror instance actually requires more worker threads than the principal. Here’s a good summary; “…database mirroring requires 2 threads on the principal server and at least 3 to 4 worker threads on the mirror server for each of the mirrored database in addition to 1 global thread on each of them. It is important to note that these calculations only reflect the number of worker threads required for administering database mirroring and additional threads are required for the core database server activity.” So, keep the worker thread capacity of the mirror instance in mind. You may need to increase max thread count (via sp_configure), limit the DBM sessions, or use a higher caliber mirror server. This KB article (quoted above) details how to calculate thread counts per CPU and points out some other ‘Things to consider when setting up database mirroring in SQL Server’ (in fact that is the title).
Initialization
If you have worked with AOAG you might be familiar with the step in the setup wizard when you can initialize an AOAG replica with the push of a button (figuratively). I love that. Alas, DBM does not have an ‘Initialize’ button. But if you are lucky enough to have a situation where your principal server backs-up mirrored DBs to a shared remote location which the mirror instance can also access you can build something along those same lines. This makes mirror builds easy and avoids taking fresh, out of cycle backups to initialize a DBM session. The following utility script does just that. It iterates through the msdb..backupset table and generates TSQL to restore the most recent full backup on the mirror side. It also generates ordered restore statements to roll on diff and tlog backups from the file share. The output includes SET PARTNER statements to initialize the session on both principal and mirror instance and should be copied into and executed in a SQLCMD window so as to leverage the :CONNECT command. With some tweaking and some manual backup file copying it could be made to work for other scenarios where backups are local or are not on a shared disk. It’s nothing too fancy, but it has saved me time and hassle especially when faced with a project that requires many DBM session to be built in a short-as-possible time. P.S. Don’t forget to disable tlog backups while you are restoring the logs. Note the script is in 2 sections because of some limits of the formatting tool – i hope you don’t mind, I’m working on that problem.
declare @principal varchar(100) =
declare @mirror varchar(100) =
declare @principalFQDN varchar(100) =
declare @mirrorFQDN varchar(100) =
declare @backupdir varchar(1000) =
declare @DB varchar(100) =
declare @path varchar(1000)
declare @SQL varchar(max)
declare @rowid int, @cnt int
declare @output table
(SQLCMD)
create table #tempdbnames
(rowid int identity(1,1),
dbname varchar(1000)
)
insert into #tempdbnames
select db_name(database_id) from sys.databases where database_id > 4 and db_name(database_id) <> 'distribution' and db_name(database_id) like @db
select @cnt = COUNT(*) from #tempdbnames
while @cnt <> 0
Begin
select @rowid = min(rowid) from #tempdbnames
select @DB = dbname from #tempdbnames where rowid = @rowid
create table #backups(
backup_start_date datetime,
type varchar(4),
physical_device_name varchar(1000),
text varchar(1000)
)
insert into #backups
select bs. backup_start_date, bs .type, mf.physical_device_name ,
'restore log ['+@DB +'] from disk = '+ ''''+ mf.physical_device_name +''' with norecovery, stats=10'
from msdb.. backupset bs
join msdb.. backupmediafamily mf
on bs. media_set_id = mf .media_set_id
where bs. database_name = @DB
and bs. type = 'L'
and bs. backup_start_date >
(select max(backup_start_date ) from msdb..backupset bs
where bs. database_name = @DB
and bs. type = 'I' )
and bs. backup_start_date >
(select max(backup_start_date ) from msdb..backupset bs
where bs. database_name = @DB
and bs. type = 'D' )
union
select bs. backup_start_date, bs .type, mf.physical_device_name ,
'restore database [' +@DB+ '] from disk = '+ ''''+ mf.physical_device_name +''' with norecovery, stats=10'
from msdb.. backupset bs
join msdb.. backupmediafamily mf
on bs. media_set_id = mf .media_set_id
where bs. database_name = @DB
and bs. type = 'I'
and bs. backup_start_date =
(select max(backup_start_date ) from msdb..backupset bs
where bs. database_name = @DB
and bs. type = 'I' )
union
select bs. backup_start_date, bs .type, mf.physical_device_name ,
'restore database [' +@DB+ '] from disk = '+ ''''+ mf.physical_device_name +''' with norecovery, stats=10'
from msdb.. backupset bs
join msdb.. backupmediafamily mf
on bs. media_set_id = mf .media_set_id
where bs. database_name = @DB
and bs. type = 'D'
and bs. backup_start_date =
(select max(backup_start_date ) from msdb..backupset bs
where bs. database_name = @DB
and bs. type = 'D' )
order by bs.backup_start_date asc
…. but wait, there’s more …..
Set @SQL = ':Connect '+ @mirror +'
'
insert @output values(@SQL)
Select @path = physical_device_name from #backups where type = 'D'
Set @SQL = 'restore database '+@DB+' from disk = ''' + @path + ''' with replace, stats =10, norecovery --full
'
insert @output values(@SQL)
set @SQL = null
set @path = null
Select @path = physical_device_name from #backups where type = 'I'
if @path is not null
Begin
Set @SQL = 'restore database '+@DB+' from disk = ''' + @path + ''' with replace, stats =10, norecovery -diff
'
insert @output values(@SQL)
set @SQL = null
end
declare cx cursor for
select physical_device_name from #backups where type = 'L'
open cx
fetch next from cx into @path
while @@FETCH_STATUS = 0
begin
Set @SQL = 'restore log '+@DB+' from disk = ''' + @path + ''' with replace, stats =10, norecovery --log
'
insert @output values(@SQL)
set @SQL = null
fetch next from cx into @path
end
close cx
deallocate cx
Set @SQL = 'alter database ' + @DB + ' set partner = '''+@principalFQDN+'''
'
insert @output values(@SQL)
Set @SQL = ':Connect '+@principal+'
'
insert @output values(@SQL)
Set @SQL = 'alter database ' + @DB + ' set partner = '''+@mirrorFQDN+'''
'
insert @output values(@SQL)
delete from #tempdbnames where dbname = @DB
select @cnt = COUNT(*) from #tempdbnames
select * from @output
drop table #backups
end
drop table #tempdbnames
Migrations
Well I suppose most everyone knows this but I can’t help mention it because I think it’s interesting. Say you have a situation where the principal instance goes down and you want to bring the mirror instance DB online. A disconnected mirrored db has a status of recovering. Leaving aside all the details around lost data and split brains and so on, how do you simply bring the DB online?
RESTORE DATABASE [BLAUGH] WITH RECOVERY;
That’s it. No FROM DISK= , no ALTER DATABASE, no nothing but WITH RECOVERY. When the principal disconnects, the mirror instance is all synched up and transactionally consistent. It’s the same situation when rolling on tlogs, if the final log is restored with no recovery, the DB just needs this last statement executed. This comes into play when doing migrations, in some cases rather than failing over the session, it can work just to disconnected the principal and run this command on the mirror DB to bring it online. All it needs is that one last RESTORE.
Partner
For a long time I considered the mirror session safety as a static setting; this DBM session is high-safety, that other one is high-performance, and so on. But struggling to keep the mirror session from getting too out of synch on a large DB during index rebuild made me start thinking of it more as a toggle switch. Turn on high-safety all production day long, switch to high-performance for nightly maintenance. Or conversely, depending on circumstances, you might find that operations that have high impact on mirror session latency can better be handled by using high-safety. This effectively guarantees the session cannot get out of synch (though it may require a longer maintenance window). So, there are a couple ways to think about it, and – assuming EE and no witness – it’s usually not a big deal to flip a session in or out of asynch and synch modes according to the need. Testing may reveal the best approach.
Po-boy’s Reporting\Testing DB
This last one is surely unsupported, but an interesting idea in my book and I actually implemented it for a time. If you need a quick copy of your DB on the mirror instance side, here is one way to do it:
- ensure the DBM session is synchronized (toggle high-safety)
- pause the session
- stop the mirror instance
- make a copy of the data and log file
- start the mirror instance and resume the DBM session
- attach the copied files as a new database to the mirrored instance
Viola, a secondary ‘snapshot’ readable copy of the mirrored DB on the mirror instance. As mentioned in the Migrations topic above, a synchronized database mirror is transactionally consistent, it just needs to be brought on line. Note, it’s been way back since SQL2005 since I tried this hack technique. If you try it, please let me know how it goes ;).
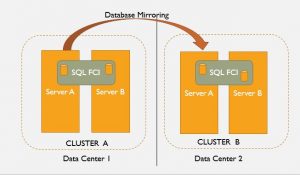
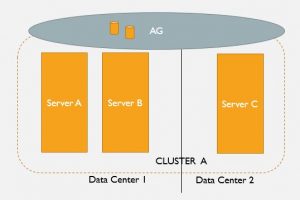
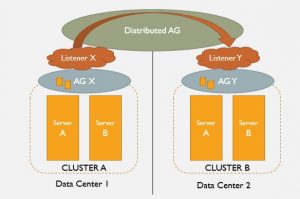






 That beanie, that smile, the pocket full of pens and gauges … this guy is capital D.B.A. personified. Way before anyone was tuning stored procedures, Goober was keeping the squad cars running like a scalded dog and making sure Aunt Bee’s Hudson made it to the market and back. Once, he disassembled Gilly Walker’s car and rebuilt it —from the ground up — in the court house!
That beanie, that smile, the pocket full of pens and gauges … this guy is capital D.B.A. personified. Way before anyone was tuning stored procedures, Goober was keeping the squad cars running like a scalded dog and making sure Aunt Bee’s Hudson made it to the market and back. Once, he disassembled Gilly Walker’s car and rebuilt it —from the ground up — in the court house! 
 night, all you have to do is call or page or email or text or skype or IM him. He’s not in his office – he’s waiting just outside your cube. He can fix anything, he can fix everything. One day at a time. And on that key chain there… he has the master key!
night, all you have to do is call or page or email or text or skype or IM him. He’s not in his office – he’s waiting just outside your cube. He can fix anything, he can fix everything. One day at a time. And on that key chain there… he has the master key!
