Remember Database Mirroring?
I do. Vaguely.
In particular, I remember working with Database Mirroring (DBM) as part of an interesting -and complex- HADR setup. Visualize a 4-node windows fail-over cluster in Data Center 1 with SQL Server installed on each node (lets call it a 4XActive). We have high-availability covered here via the clustered instance. Given an outage for any given node, the SQL instance will move (fail-over) to another node.
On the other side of town, in Data Center 2, is another 4XActive.
Now, here’s the DR part. Every database on each instance is replicated from Data Center 1 to Data Center 2 via DBM. To explain, here’s a ppt slide I’m borrowing from my recent presentation on this stuff:
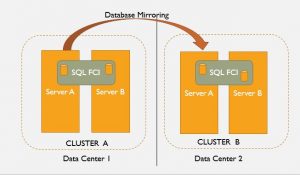
This worked! Pretty well in fact. But of course, knowing what I know now, I clearly remember the limitations and paint points:
- Single point of failure in the cluster’s shared disks hosting database files
- No “readable” replica for scale-out reads (we use transnational replication to create a report instance)
- No automatic fail-over – yeah DBM has auto-fail-over capability but I’m thinking more about application connections… it was not easy to quickly re-direct connections from DC1 to DC2.
- No grouped database fail-over (in this case, up to 4 database were related (tenant architecture) and there was no easy method of failing them over a unit)
I bet you saw this coming, but the answer to these limitations -and others like them- came along when SQL introduced Availability Groups.
HADR and Availability Groups
A basic availability group will solve for HA via a synchronous fail-over replica partner, and scale-out reads via a readable replica. But it gets a bit more complicated if you need to build-in DR as well. Here’s another slide to illustrate one option to add DR to your HA using Availability Groups:
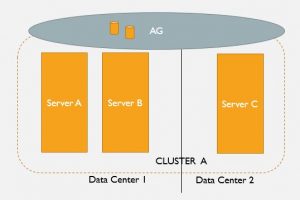
In this case we add a cluster node in a remote data center to a standard AG configuration. This is the DR node (and it might also serve dual duty as the read-replica). Seems legit, right? But what are the drawbacks? To my thinking, there is a lot of management complexity. Consider the configuration and administration of a cluster over WAN and multi-domain and\or multi-subnet clusters.
Which bring us to …. Distributed Availability Groups
What if you could have the best of both worlds? Local availability groups in both the production and DR data centers, optional scale-out reads on the DR side, and replication between the two?
Tada!
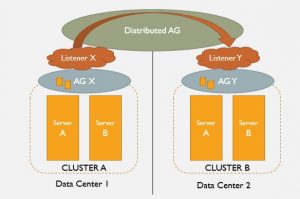
Check it out, that is just what we get with Distributed Availability Groups.
Thanks for reading, please stay tuned for more on this topic…