I wanted to check out the ideas presented by the SQLCAT team here to tune backup processes: Tuning the Performance of Backup Compression in SQL Server 2008
To follow along with the suggested trials, I took a series of backups of a ~50GB database on a test instance and captured duration, backup thru-put and CPU to narrow down optimal backup parameters. The test instance I used is SS2008 64-bit EE running on a Win2008 box with 148GB RAM and 64 CPU. I used perfmon counters to capture thru-put and % processor time and noted the backup results to capture the durations
According to the suggestions I ran a backup to disk=’nul’ for buffercounts 50 through 600 and including the baseline default of 7. This highlights what might be the optimal buffercount to increase backup speed without unduly taxing the CPU.
As you can see, duration improves significantly with non-default buffer counts:
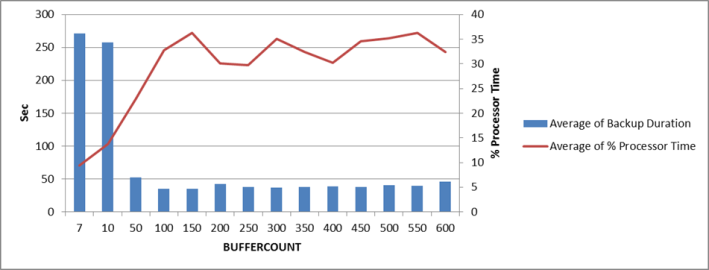
Also, not surprisingly, throughput increases correspondingly:
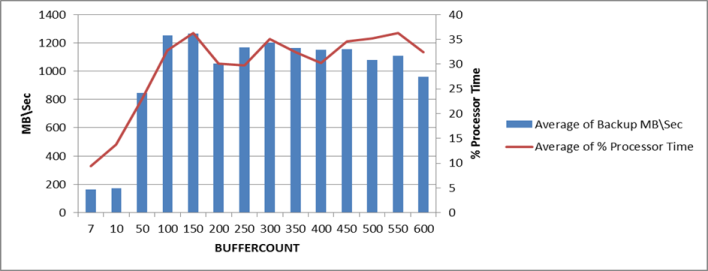
Of course the speed and throughput are at the cost of CPU time, however there is an apparent sweet-spot here at buffercount ~100 which gives us the best performance with the least cost. Higher buffercounts do not seem to offer further improvements.
So, accepting a buffercount of 100-150 is the optimal setting, I proceeded to run a few tests writing the backups to the actual file share used. As suggested might be the case by the SQL CAT team, writing the backup to file is indeed the limiting factor in speeding up backups. However, considering the baseline default buffer count (7) vs a buffer count of 100-150 we might still realize a significant performance increase in backup speeds.
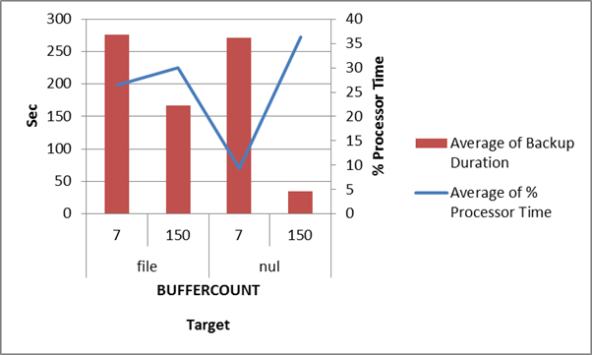

Using these findings I was able to convince my team to implement buffercount = 100 for the standard backup jobs and decreased backup duration for several key instances. More importantly, the DBA team now utilizes the buffercount argument when replication teardownrebuilds are required for some time-critical project work and the replication is (re)built using initialize-via-backup methods.


